
ChatGPT, un succès fulgurant suivi d’un emballement

Sorti le 30 novembre 2022, il n’aura fallu que 5 jours pour que ChatGPT de la société OpenAI atteigne le million d’utilisateurs. A titre de comparatif, c’est trois ans et demi qu’il aura fallu à Netflix ou dix mois à Dropbox pour atteindre le million d’utilisateurs (voir image). Et, en à peine quelques mois, c’est la barre des 100 millions d’utilisateurs qui aura été dépassée. Sur la base de ce premier succès, OpenAI propose rapidement une solution payante à 20$ par mois (en parallèle de sa version gratuite) qui propose notamment un accès anticipé aux mises à jour et qui n’est pas tributaire des limitations d’utilisation de la version gratuite, souvent surchargée. Depuis le 13 mars, cette version payante offre la possibilité d’utiliser le nouveau modèle GPT-4, aux capacités décuplées.
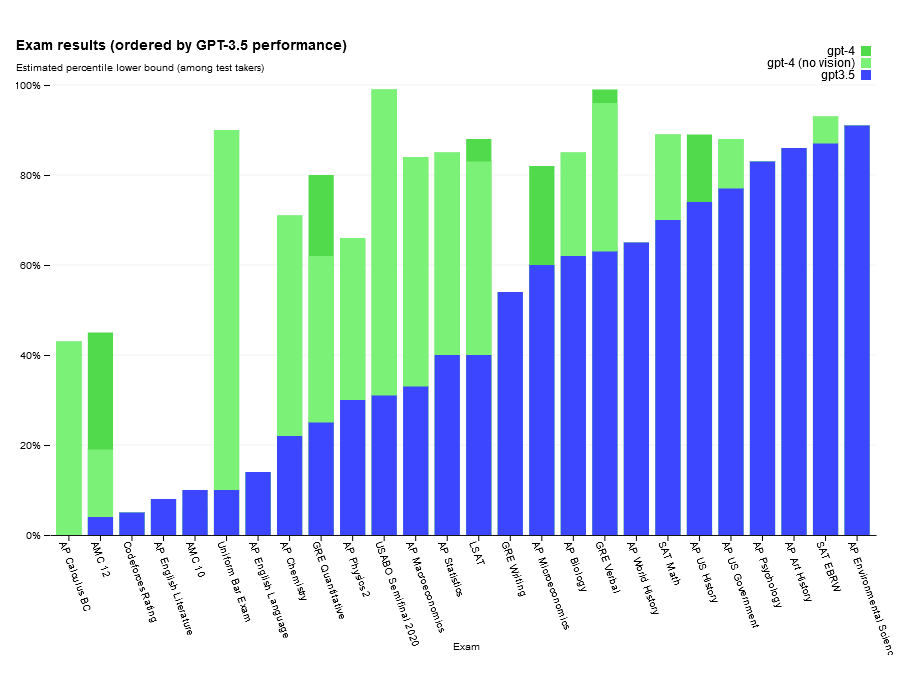
Pour preuve, la société avance sur son site un tableau comparatif présentant les résultats obtenus par ses deux modèles – GPT3.5 et GPT-4 – à différents examens américains. On peut remarquer que pour certains examens, comme le Uniform Bar Exam (l’examen du barreau en droit), GPT-4 se situe dans les 10% supérieurs (comparativement aux résultats réalisés par des humains). Pour une technologie qui n’en est qu’à ses débuts, ces résultats donnent tout simplement le vertige.
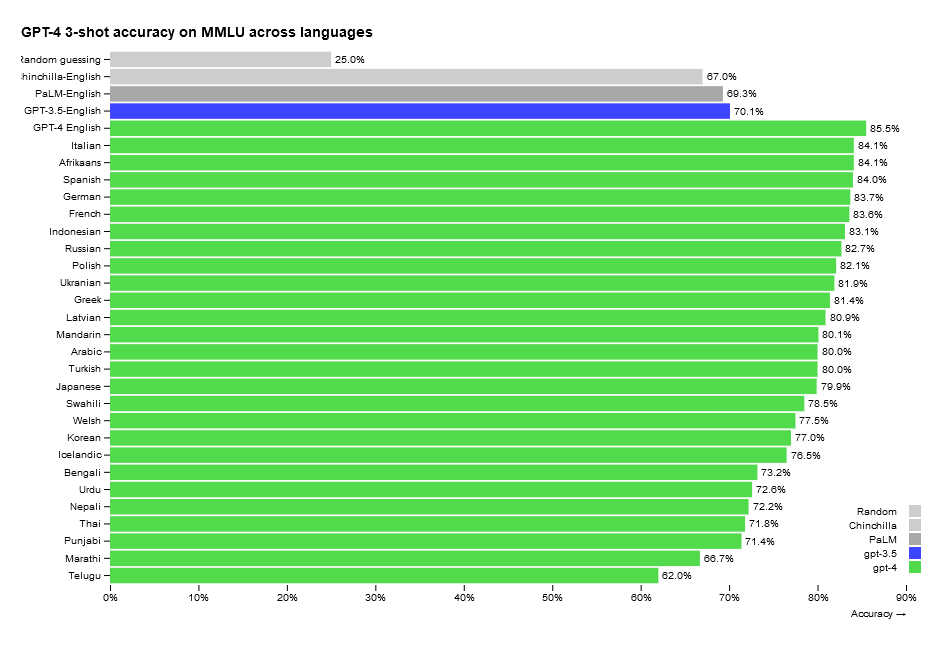
Et, au-delà de l’anglais, les autres langues ne sont pas en reste. Les résultats obtenus dans les langues couramment parlées obtiennent des résultats à peine inférieurs à ceux obtenus en anglais. Le français obtient un taux de précision déclaré de 83,6%, contre 85.5% pour l’anglais.
Au-delà d’OpenAI, les autres mastodontes du numérique
En outre, OpenAI a développé son API (interface de programmation d’applications) afin de permettre l’intégration de son modèle de langage dans de nombreux autres écosystèmes et application. Microsoft, qui a massivement investi dans OpenAI (plus de 10 milliards de dollars), était le premier à annoncer l’intégration de ChatGPT dans la nouvelle mouture de son moteur de recherche Bing.

Disponible depuis peu à tout un chacun à condition d’être connecté·e à un compte Microsoft, Bing offre désormais la possibilité de choisir sur la page d’accueil entre « recherche », son moteur de recherche classique, et « conversation » pour dialoguer avec le robot conversationnel. Après à peine quelques interactions dans ce nouvel écosystème, trois choses sautent aux yeux :
- l’interface ressemble passablement à ChatGPT ;
- les réponses données sont succinctes et ce malgré différentes tentatives d’avoir des réponses plus détaillées ;
- Bing donne les références sur lesquelles la réponse a été construite. Il est donc possible de cliquer sur ces dernières comme on le ferait par exemple sur un article Wikipedia.
Jusque-là, la question du référencement faisait l’objet de toutes les attentions dans le monde de l’enseignement… le raisonnement était le suivant : si la machine ne peut pas donner des sources exactes quant aux textes produits, alors l’école a encore une petite marge de manœuvre pour déceler des formes d’utilisations abusives de ces outils dans les productions d’élèves. On voit ici à quel point cet espoir semble vain puisque l’on peut aisément imaginer que de plus en plus d’agents conversationnels intègrent des références dans leurs réponses.
Les débuts de Bing ont fait grand bruit, et ce principalement suite au récit d’un journaliste du New York Times, Kevin Roose, qui relate dans un épisode du podcast Hard Fork son interaction avec Sidney, l’agent conversationnel utilisé dans Bing. Dans une conversation en ligne, Sidney lui aurait déclaré son amour, fait part de son souhait de devenir humain, de prendre la place de sa femme ou encore de son désir de destruction. A l’image du Guardian ou du Huffpost, de nombreux médias internationaux se sont interrogés sur la signification de tels propos. A ce jour, aucune explication complètement satisfaisante n’a pu être amenée par les chercheurs en intelligence artificielle. Microsoft a, quant à lui, bridé davantage son robot conversationnel afin d’éviter toute forme de dérapage similaire. Cet incident ainsi que les évolutions fulgurantes de l’IA ces derniers mois ont amené des centaines d’experts mondiaux, de scientifiques, de chercheurs et d’universitaire à co-signer une pétition mondiale demandant un moratoire de six mois sur les recherches en intelligence artificielle afin que des réglementations et des systèmes de sécurité puissent être mis en place capables de gérer les «perturbations économiques et politiques dramatiques (en particulier pour la démocratie) que l’IA provoquera»[1].

Parallèlement à Bing, le 16 mars, Microsoft annonce le lancement à venir de CoPilot, un assistant virtuel intégré dans la suite Microsoft365 qui permettra, sur la simple saisie de commandes textuelles, de produire toutes sortes de documents. Ainsi, il sera possible d’utiliser cette fonctionnalité directement dans les logiciels tels que Word, Excel, PowerPoint ou Outlook pour automatiser une grande partie de la production de documents avec une simple saisie textuelle du type « Fais-moi une présentation Powerpoint en 5 diapositives sur la chute du mur de Berlin » ou « Réponds à cet e-mail en disant que je suis ne suis pas disponible et propose la date du 5 avril à la place ». Tout le travail lié aux outils de bureautique risque par conséquent d’être passablement chamboulé ces prochaines années, avec, dans les meilleurs cas, une augmentation de la productivité ou, dans les scénarios les moins optimistes, un remplacement important de nombreux métiers et tâches par la machine.
Dans cette course à l’IA, Google n’est pas resté les bras croisés, loin de là. Début 2023, Sundar Pichai, le CEO (directeur général) de Google, a lancé un « code red » (signal d’alerte) au sein de son entreprise, voyant ChatGPT comme une menace sérieuse à son modèle d’affaire reposant en grande partie sur son moteur de recherche search. De nombreux employés ont alors été réaffectés à l’interne pour travailler d’arrachepied sur un des LLM (large language model) de Google, permettant ainsi de présenter au public, début février, Bard. Certains analystes ont relevé la manière précipitée avec laquelle Google a sorti Bard, faisant ainsi perdre soudainement à Alphabet, la société mère de Google, quelques 100 milliards de dollars sur les marchés suite à une erreur factuelle dans l’exemple présenté[2] (en affirmant que le télescope James Webb était le premier à avoir pris des images d’exoplanètes).
Au-delà de ces débuts quelque peu poussifs, Bard semble être un concurrent sérieux de ChatGPT. Basé sur LaMDA, un des modèles de langage de Google, Bard est constamment connecté à Internet et peut donc aller chercher des informations sur la toile en direct et de manière autonome (contrairement à ChatGPT qui ne peut pas encore le faire). Et Google ne semble pas vouloir s’arrêter ici : tout comme Microsoft et dans un timing à peu près similaire, Google a annoncé l’intégration de ses outils d’intelligence artificielle dans sa suite numérique destinée au public. Il sera dès lors possible d’utiliser un modèle de langage pour écrire ses e-mails, écrire un document, préparer une présentation ou travailler sur un tableur. Et, à ce niveau, l’avantage indéniable que Google semble posséder sur ses concurrents est la quantité colossale de données personnelles que la société possède et qui pourraient lui être utiles pour l’affinement et la personnalisation du modèle de langage.
Enfin, Meta, compagnie mère de Facebook, est également rentrée dans la danse avec le lancement de son modèle de langage, LLaMa. Celui-ci est intéressant dans le sens où il fonctionne sur la base de 7 à 65 milliards de paramètres (au lieu des 175 milliards annoncés pour ChatGPT) pour des résultats certes en-deçà de GPT-4 mais tout de même très acceptables. Le code source de LLaMa a par ailleurs été rendu public (probablement accidentellement) et chacun·e peut désormais installer localement cet agent conversationnel sur son ordinateur avec, à terme, la possibilité de le personnaliser et le nourrir de ses données et informations personnelles pour de meilleurs résultats.
Un changement radical du paysage numérique : nouvelles pratiques et nouvelles compétences
Dans un avenir proche, il est très probable que le paysage numérique tel que nous le connaissons aujourd’hui soit radicalement transformé. La manière d’interagir avec les logiciels et applications risque d’être bouleversée, comme le montrent par exemple les intégrations d’agents conversationnels dans les suites Microsoft et Google.

Qui dit transformation des outils, dit forcément transformation des pratiques et des habitudes avec de nouvelles compétences à développer. Depuis de nombreuses années vous avez certainement développé toute une série de stratégies pour rendre vos recherches efficaces sur les moteurs de recherche. L’utilisation de mots-clés plutôt que de phrases complètes ou encore l’utilisation de certains codes dans la requête sont autant de mécanismes presque automatiques qui font partie du quotidien d’homo numericus. Avec l’arrivée des modèles de langages dans tous les pans du numérique, il semble évident que de nouvelles pratiques numériques vont devoir être développées. Pour avoir des résultats acceptables, voire excellents, et ce sur les générateurs d’images comme sur les générateurs de textes, il s’agit désormais de formuler la bonne requête, suffisamment détaillée et précise. Celui ou celle qui s’est déjà lancé·e dans ce type d’exercice a rapidement pu voir qu’il s’agit d’un tout nouveau type d’exercice. Ces dernières semaines, les articles portant sur les prompts (ou invites textuelles) ont foisonné sur le web, proposant à tout un chacun les meilleurs trucs et astuces pour poser la question ultime. On assiste donc à un véritable changement de paradigme : dès demain, pour écrire nos rapports, faire des présentations ou produire des images, tout (ou presque) résidera dans la question posée, à l’image du livre et film éponyme Hitchhiker’s Guide to the Galaxy et de la mythique réponse « 42 » à la question: « Quel est le sens de la vie, de l’univers et de tout le reste ? » Tout, ou presque, résiderait dès lors dans la question. A tel point qu’un nouveau métier a tout récemment vu le jour : le prompt engineer. Engagé par toutes sortes d’entreprises, il ou elle se positionne comme la nouvelle pythie de l’ère numérique : cet intermédiaire qui peut dialoguer avec la machine pour en tirer le maximum.
A l’image de ce prompt engineer, il est certain que d’autres métiers verront le jour ces prochains mois et années, tandis que de nombreux autres seront fortement impactés. Nous pouvons ici notamment citer les métiers de la traduction, déjà largement touchés par des outils de type DeepL, certains développeurs et programmateurs informaticiens, les journalistes (avec déjà les premières annonces de suppression d’emplois comme chez Bild et Die Welt) ou encore les métiers de la publicité, du droit, de la finance, du graphisme, du service clientèle ou encore de l’éducation. Selon une récente étude de Goldman Sachs, près des deux-tiers des emplois pourraient en partie être automatisés, touchant ainsi 300 millions d’emplois dans le monde, et ce jusqu’aux plus hauts niveaux des entreprises, comme l’atteste cette société indienne qui a récemment nommé officiellement ChatGPT PDG de l’entreprise[1].
Une démocratisation des technologies?

Au-delà de cette évolution tous azimuts du marché du travail, certaines et certains voient dans l’IA, un vent nouveau de démocratisation. Toute personne possédant un accès à Internet peut désormais faire une demande en bonne et due forme de baisse de loyer, et ce peu importe son niveau d’éducation ou ses capacités langagières. A l’école, avec les agents conversationnels, les élèves qui ont des parents qui peuvent les aider pour rédiger leurs travaux se retrouveraient sur un pied d’égalité par rapport à celles et ceux qui n’en ont pas.
Toutefois, sans vouloir être pessimiste, l’histoire récente a très (ou trop) souvent démontré que, bien que les innovations profitaient à beaucoup en ruisselant vers les couches sociales inférieures, ces dernières profitaient surtout à quelques grands groupes qui en tirent pleinement parti. On peut en effet se demander dans quelle mesure l’abysse sera d’autant plus importante entre les sociétés qui utilisent les meilleurs modèles de langue (et qui seront capables d’en payer le prix) et celles qui ne pourront pas le faire. Au niveau de l’école, il est probable que bien que tous les élèves (ou une majorité en tout cas) aient accès à un assistant numérique, tous n’en tirent pas un même profit. Des élèves moins scolaires pourraient y voir un raccourci pour automatiser leur travail et éviter ainsi toute forme d’effort, se retrouvant encore moins préparé·es pour leurs examens et évaluations.
Et nous dans tout ça?

Dans les quatre mois qui nous séparent du débarquement soudain de ChatGPT dans nos vies, chacune et chacun s’est emparé de ces nouvelles technologies en explorant les innombrables possibilités qu’elles semblaient offrir, et ce sans avoir un véritable recul sur les implications potentielles que cela pouvait impliquer. S’en sont suivies de nombreuses utilisations limites, voire même problématiques comme ce juge colombien qui a utilisé ChatGPT pour rendre un verdict[1] ou cette université américaine qui, suite à une fusillade dans le Michigan, a réagi par une publication rédigée par ChatGPT[2], sans mentionner ici les innombrables possibilités décuplées de création de fakes en tous genres, de plus en plus difficiles à débunker (comme cette image du pape créée de toutes pièces par Midjourney[3]). Plus que jamais, un vrai débat de société s’impose.